
Matching Job Descriptions and Resumes Using Deep Learning Algorithms - Jio Institute
 The task of matching job descriptions and resumes using machine learning algorithms to output a Skill Match Index in percentage is a complex problem. It involves several challenging tasks, including data cleaning and preparation, feature extraction, algorithm selection and training, and metric evaluation. To accomplish this task, expertise in NLP, machine learning, and data science, as well as a deep understanding of the job market and hiring practices, is required. However, with the help of new technologies in NLP, we aim to improve the performance of the ATS system.
The task of matching job descriptions and resumes using machine learning algorithms to output a Skill Match Index in percentage is a complex problem. It involves several challenging tasks, including data cleaning and preparation, feature extraction, algorithm selection and training, and metric evaluation. To accomplish this task, expertise in NLP, machine learning, and data science, as well as a deep understanding of the job market and hiring practices, is required. However, with the help of new technologies in NLP, we aim to improve the performance of the ATS system.
Reproduce the below technique yourself with this notebook.
As advancements in deep learning are outperforming humans, we have also applied state-of-the-art deep learning algorithms to achieve our goal.
Dataset Description
To tackle this problem, we will be using the UpdatedResumeDataSet.csv dataset, which is available on Kaggle. This dataset consists of data points from the IT domain and has two columns: categories (job description) and Resume. We chose only the IT domain to create a baseline model that could prove our technique to be beneficial or not.
Real-World Challenges and Constraints
In the practical world, there are no rigid time constraints for calculating the degree of match between job descriptions and resumes. This calculation can be performed daily, hourly, or after the submission deadline. Similarly, scalability is not a significant concern, as strict latency requirements do not exist.
While interpretability of the model is not mandatory, it is desirable to have. To achieve interpretability, we can extract keywords from the resume or use LIME or SHAP for explanations. The primary challenge we may encounter with the model is the possibility of missing out on suitable candidates if the model produces a low match value for a well-suited candidate. Conversely, if the model produces a high match value for an unsuitable candidate, we may have a large pool of unsuitable candidates.
We can fine-tune a model easily in places where we have massive amounts of relevant and labeled data, using a simple supervised fine-tuning approach. Unfortunately, these scenarios are few and far between. It is for this reason that existing models have a limited scope. Therefore, we need to explore other techniques to improve the performance of the ATS system.
Applying Deep Neural Network for Job Description and Resume Matching
To leverage the benefits of deep neural networks, we aim to avoid extracting data by cleaning it. This will help prevent any loss of information and enable the model to train with fewer biases. Instead, we will apply data pre-processing to create more structured data.
Our approach is to fine-tune the model to produce a task-centric labeled dataset and generate sentence embeddings that align with our given tasks. We will use these embeddings in a distance formula to score the distance.
To improve the accuracy of our model, we can perform more analysis in iterations.
Data Preprocessing
We will apply the following data preprocessing steps:
- Drop NULL columns
- Remove special characters
- Reduce text to 400 words/tokens
- Convert to JSONL for easy data loading
Deep Learning Technique
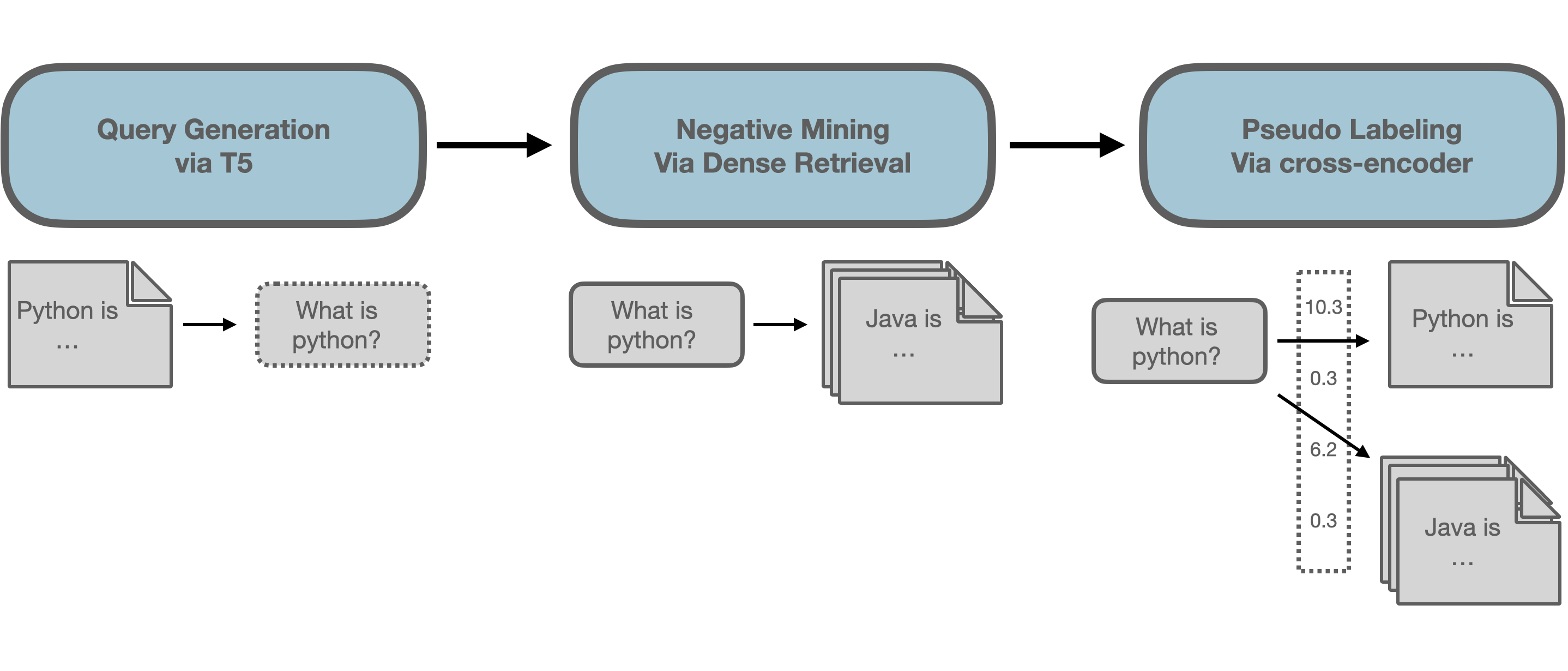
Since we don’t have labeled data, we will be applying a mixture of unsupervised learning algorithms to generate labels and then score them to train our model. We will fine-tune the pre-trained model to optimize its performance for our specific task.
We followed the following steps to train our model, where we explain the sub-problem and solution in each step.
-
Problem: We don’t have labeled data. Solution: To address this issue, we applied the technique called Domain Adaptation with Generative Pseudo-Labelling (GPL). This approach is more effective than traditional unsupervised learning methods for text embedding learning, as it is better at learning domain-specific concepts. With domain adaptation, we can use an unlabelled corpus from our specific domain along with an existing labeled corpus to generate labels.
- Query Generation: For a given text from our domain, we used a T5 model to generate a possible query for the given text. For example, when our text is “Python is a high-level general-purpose programming language,” the model generates a query like “What is Python?”
Input: Paragraph: ted the documentation to provide the disaster recovery processes. database administrator ceige havana, il september 2007 to october 2014 ceige, la havana cuba produced entity relationship data flow diagrams, database normalization schemata logical to physical database maps, and data table parameters. installed and managed database server created and monitored user accounts, user permissions, database extents and table partitions. implemented robust backup and recovery procedures based on data volatility and application availability requirements monitored and optimized system performance using index tuning, disk optimization, and other methods. monitored the size of the transaction log. managed databases on multiple disks using disk mirroring technology... output: Generated Queries: 1: what is the definition of database administrator 2: what did database administrator ceige 3: what is a database administrator - Negative Mining: In this step, we aim to find passages that are similar to the generated query but are not relevant to the user’s search intent. To achieve this, we use dense retrieval with an existing text embedding model to retrieve relevant paragraphs for the query. These relevant paragraphs serve as positive samples, while we need to mine negative samples that are similar to the query but are not relevant. For instance, for the query “What is Python?”, a negative sample could be “Python is a species of snake found in Australia.”.
output:
Negative sampling
1. what is python?
2. what is database
3. what did database administrator do
-
Pseudo Labelling: In this step, we use a Cross-Encoder to score all (query, passage)-pairs to identify relevant passages for the query. This is important because some of the passages retrieved in the negative mining step may actually be relevant for the user’s search intent. The Cross-Encoder assigns a score to each (query, passage) pair, indicating how relevant the passage is to the query.
-
Training: Once we have generated the triplets (generated query, positive passage, mined negative passage) and the corresponding Cross-Encoder scores for (query, positive) and (query, negative), we can start training the text embedding model using MarginMSELoss. This loss function ensures that the distance between the positive and negative passages is greater than a specified margin.
Overall, these steps aim to fine-tune a pre-trained model to learn domain-specific concepts and improve the performance of the model in a specific task. Further analysis can be done at each iteration to improve the accuracy of the model.
By following these steps, we were able to train a model that can match job descriptions and resumes accurately and effectively.
Try the demo below.